Sources of information
When evaluating FOSS projects there are many potential sources of information, which in many cases, and specially when the project follows the open development paradigm, are public. Some of these sources are:
- Source code management systems (SCM), such as git, Mercurial or Subversion. All changes to the source code, and in some cases, to documentation and other related artifacts, are stored in them. From these systems we can extract any past version of the source code, which allows for code analysis, code inspection, etc. SCM systems store metainformation for every change, which usually includes who authored and committed it, when, the files involved with the corresponding diffs, etc.
- Issue tracking systems (ITS), also names ticketing systems or bug reporting systems, although they are used for much more than reporting bugs. Most projects use them for tracking how bugs are reported and fixed, and how new functionality is proposed, defined and built. But they can also use ITS for tracking the policy decision or the code review process, or even for tracking how the infrastructure is managed. Their repositories are usually modeled as tickets, which experiment changes in state until they are closed. Some examples are Bugzilla, Lanuchpad, GitHub Issues, Allura Tickets, Trac or RedMine.
- Code review systems (CRS). Used to track the code review process. They are usually modeled very similar to ITS, but specialized for code review, and in many cases integrated with SCM. Some examples are Gerrit and GitHub Pull Requests.
- Asynchronous communication systems (ACS). The most classical ones are mailing lists and forums. But more recently others are emerging, such as question/answer systems, of which StackOverflow and Askbot are good examples. The repositories for ACSs are usually modeled as messages, grouped in threads, either implicit or explicit. Each message includes content, but also metainformation such as author, date, etc.
- Synchronous communication systems (SCS). Some examples of them are IRC or more recently, Slack.
- Testing and continuous integration systems (CI). Some examples are Jenkins, Hudson and TravisCI.
- Web sites and other repositories for content related to the project. They may include documentation, download areas with binaries ready to run, etc.
All these systems usually offer means for persons to interact with them, which can be used to get a first hand impression of how the project is using them. Qualitative evaluations can benefit from this kind of browsing of information. This can be done, for example, by reading comments in commit records, messages in mailing list archives or IRC logs, or the history of tickets in ITSs.
It is also possible to use tools to retrieve information from them, usually via APIs designed for that matter. This allows for the automated retrieval of information for performing quantitative evaluation, or for storing all the data in a database for further analysis.
Source code management systems
Information in SCMs is usually organized in "changes", which in most systems are named "commits". The information stored with each change is different for different SCM systems, but it always incude the change itself (some way of identifying which lines were affected by the change, and how), and some metainformation. The metainformation is about who and when produced the change, and some other information related to it. For example, in the case of git, that metainformation associated with each change includes:
- A unique identifier for the commit (dubbed the "commit hash").
- The commit id of the previous commit(s) in the history of the repository.
- An identifier for the author (the person writing the change).
- An identifier for the committer (the person committing the change to the repository).
- Dates for authoring and committing actions.
- A comment produced by the author of the change.
- Complete diff with the changes (differences introduced by the change with respect to the previous situation).
An example of a git commit record
To illustrate how to obtain this information, see below an example. It is the information in a git commit record, as produced using the command git show --pretty=fuller for a commit in the CVSAnalY repository (excluding the diff):
commit 364f67f13b0046c0a0a688b30a1341ff9946ac26
Author: Santiago Dueñas <sduenas@bitergia.com>
AuthorDate: Fri Oct 11 12:55:44 2013 +0200
Commit: Santiago Dueñas <sduenas@bitergia.com>
CommitDate: Fri Oct 11 12:55:44 2013 +0200
[db] Add author's commit date
Some SCMs, like Git, make a distinction between the dates when
the committer and author pushed the changes.
...
The first line shows the commit hash, the next four are the authoring and committing identifiers and dates. In this case, author and committer are the same person, and authoring adn committing dates are the same. After those come several lines with the comment produced by the author, describing the change. After the comment comes the diff, with the list of changes (which were ommitted in the snippet, see below).
The raw information in the commit record can be obtained with git show --pretty=raw:
commit 364f67f13b0046c0a0a688b30a1341ff9946ac26
tree c121da67fcba250490b6b326deae46f041b76626
parent 99acc4d7762e3773751f17ae9f0b58169f5e4de0
author Santiago Dueñas <sduenas@bitergia.com> 1381488944 +0200
committer Santiago Dueñas <sduenas@bitergia.com> 1381488944 +0200
[db] Add author's commit date
Some SCMs, like Git, make a distinction between the dates when
the committer and author pushed the changes.
...
This format is harder to read for humans, but includes more information (such as the previous commit, or "parent"), and is therefore more useful for mining data.
The first lines of the diff that was omitted for the above commit are shown below:
diff --git a/pycvsanaly2/DBContentHandler.py b/pycvsanaly2/DBContentHandler.py
index 579e103..4b0066d 100644
--- a/pycvsanaly2/DBContentHandler.py
+++ b/pycvsanaly2/DBContentHandler.py
@@ -149,7 +149,7 @@ class DBContentHandler (ContentHandler):
self.actions = []
profiler_stop ("Inserting actions for repository %d", (self.repo_id,))
if self.commits:
- commits = [(c.id, c.rev, c.committer, c.author, c.date, c.message, c.composed_rev, c.repository_id) for c in self.commits]
+ commits = [(c.id, c.rev, c.committer, c.author, c.date, c.author_date, c.message, c.composed_rev, c.repository_id) for c in self.commits]
profiler_start ("Inserting commits for repository %d", (self.repo_id,))
cursor.executemany (statement (DBLog.__insert__, self.db.place_holder), commits)
self.commits = []
diff --git a/pycvsanaly2/Database.py b/pycvsanaly2/Database.py
index dacf406..9b02909 100644
--- a/pycvsanaly2/Database.py
+++ b/pycvsanaly2/Database.py
The first lines of the diff shows how to invoke the diff command to produce the output for the first file changed by the commit (a refers to the situation before the change, b to the situation after the change). Lines changed are those starting with - (removed) or + (added). In this case, a change in a line is modeled as removing the old line and adding a new one with the change.
Notes on using information from SCM systems
Identifiers for authors and committers are usually a name and an email address. But in some cases, such as Subversion, only a user name is available.
In decentraliized SCMs, such as git, dates for authoring and committing include local timezones, usually those of the computer in which the corresponding action was performed. This allows for timezone analysis to infer regions where developers work. In addition, since times are local, studies on daily schedules can also be performed. But in the case of centralized SCMs, such as Subversion, those dates are for the server where commits took place, which means that no information about local time for developers is avilable.
The information in the SCM allows for the reconstruction of the whole history of the repository. In the case of git, the information about the previous commit or commits (in the case of merges, there is nore than one previous commit) allows for the recovery of the full history of the repository. Using that information and some other hints, you can decide to which branch a change was committed.
The complete diff whcih is available for each change allows for the complete reconstruction of the code modifications, which is the ultimate reason for storing it. But it can be used for infering the files involved, the size of the change, and other parameters.
It is important to note that, from a historical point of view, the information provided by the SCM system is now always reliable. For example, in the case of git, developers can "rewrite" history, when they ammend or rebase. Therefore, a current retrieval of information from a git repository may show different data for some commits in the past than a similar retrieval done some time ago, or even a dfferent list of commits. For systems which only commit with an automated tool after code review, which checks and forbids history rewrites, this is not an issue. But most projects do not have specific rules or technical measueres to avoid history rewrittings, and therefore any results about past history need to be understood as "current past history".
Issue tracking systems
Information in issue tracking systems is usually organized in "tickets". This is why they are also called ticketing systems. In fact, the job of the ITS is to track the changes to each ticket. Therefore, most ITS maintain both a record for each ticket with its current state, and a history of all changes to their state, or a list of past states.
The information usually found for a ticket is:
- Identifier. Unique identifier for each ticket.
- Summary. A one line text summarizing the purpose of the ticket.
- Description. A longer description of the purpose of the ticket. This can be reporting a bug, requesting a feature, or starting a new task, for example.
- Opening date. When the ticket was opened.
- Ticker opener. An identifier for the person opening the ticket. Depending on the ITS, this can be a full name, an email address, or a user name.
- Ticket asignee. The person asigned by the project to deal with the ticket.
- Priority. A number or a text informing about the priority for the ticket. This is usually set by the ticket opener, but can be later adjusted by developers.
- State. A tag with the current state of the ticket. Examples of states are "open" (ticket opened, but still not dealt with by the project), "assigned" (ticket already assigned to some developer), "fixed" (ticket is considered to be fixed), "closed" (the issue is considered to be done).
Almost all fields in the ticket are subject to changes. When this happens, the change is recorded, including information about who made the change, when, and what the change was about.
In addition, a ticket usually have an associated list of comments. These comments are posted by the different persons who contribute to close the ticket. Some of them may be from the ticket opener, such as when a clarification is posted. Some others may be from people interested in the ticket, such as other people experiencing the same problem. Some others may be by developers trying to solve the issue. Each comment is composed by some text (the comment itself), the posting date, the author of the comment, and maybe some other fields.
But despite having a similar structure, tickets in different ITS may be presented to users in very different ways, as is shown in the next examples.
Example of ticket in GitHub
In GitHub, tickets are called "issues". They are presented in a single HTML page, showing the description, history and comments in it. Most of the current state is shown in the right column.
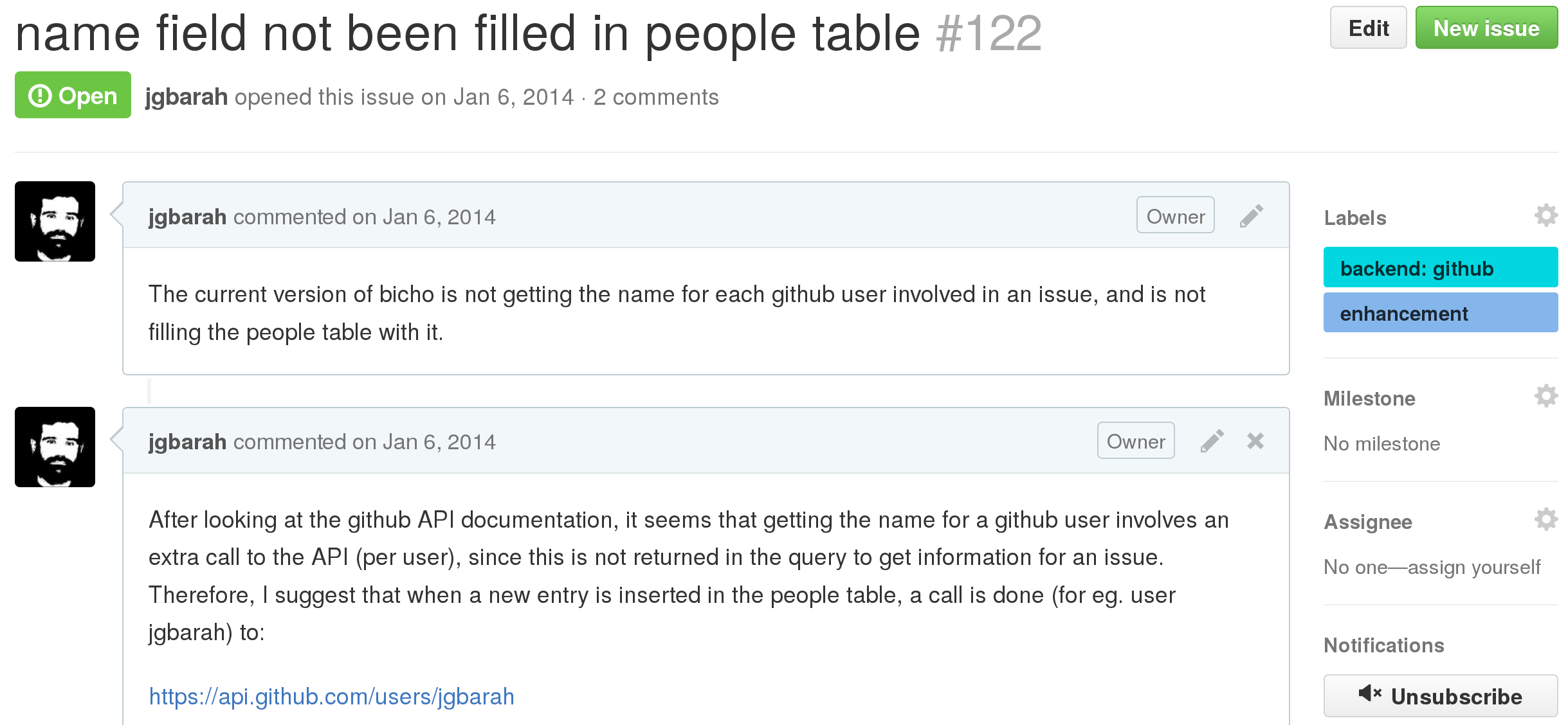 Example of ticket: GitHub issue from the Bicho project. The most relevant fields can be observed. The first text on the left column is the description of the ticket, the second one is a comment.
Example of ticket: GitHub issue from the Bicho project. The most relevant fields can be observed. The first text on the left column is the description of the ticket, the second one is a comment.
GitHub also provides the same information via the GitHub Issues API, which is easier to use for automated retrieval of information.
Example of ticket in Bugzilla
In Bugzilla tickets are called "bugs". Bugzilla is one of the earliest free software ITS, and is currently in use by some very large communities, such as Eclipse. In the following example, the status information for a ticket is shown. Below that area, the list of comments to the ticket is found, starting by its description.
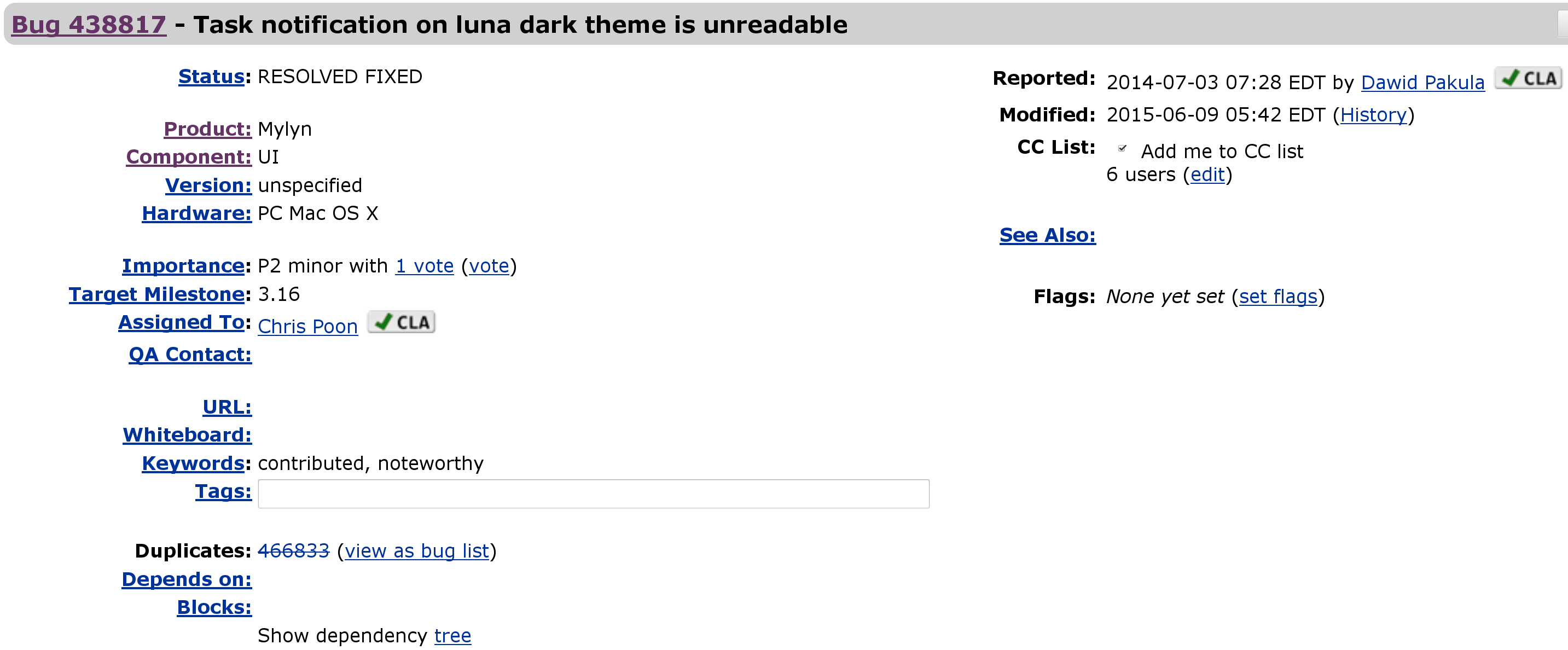 Example of ticket: Bugzilla issue from the Eclipse Mylin project. Comments come below this status information.
Example of ticket: Bugzilla issue from the Eclipse Mylin project. Comments come below this status information.
Bugzilla provides similar information via an XML file, which is more suitable for automated retrieval.
Notes on using information from an ITS
First of all, it is important to notice that projects may use tickets for many different kinds of actions. The most known one is reporting a bug, and that's the reason why these systems are also called "bug reporting systems". But tickets may refer to feature requests, tasks being performed, or even policy discussions. It is up to the policies and uses of a project to decide what kind of communication they channel through the ITS, and that varies a lot from project to project. Therefore, counts on for example "open tickets" are different from counts on "open bugs".
ITSs are also very different on which kind of information they store, and what does it mean. For example, all of them include some kind of encoding the "state" of the ticket. But while GitHub uses tags for that, Bugzilla uses a "status" field. In addition, each project may use this information in different ways, and in many cases they define their own tags, status fields, or whatever the ITS uses for this. That makes it very difficult to know at first sight even when a ticket is a bug, or when a bug is actually fixed. The workflow for tickets, and how and who can move them from state to state, is usually project-defined,although the ITS may constrain or recommend about it. For example, the next figure shows the recommended workflow for Bugzilla.
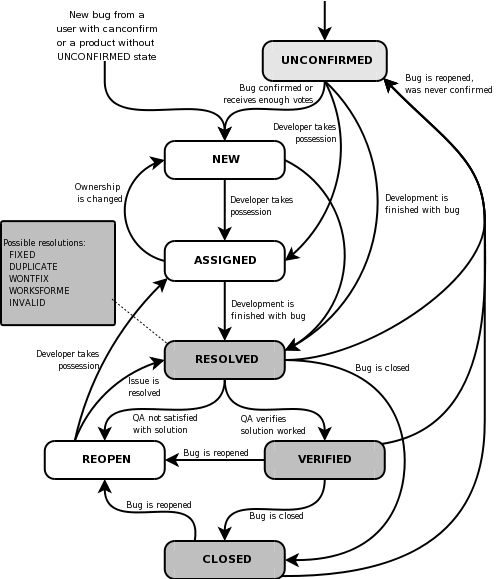 Recommended workflow in Bugzilla. Original figure illustrates Life Cycle of a Bug, in The Bugzilla Guide - 3.6.13 Release distributed under the GNU Free Documentation License.
Recommended workflow in Bugzilla. Original figure illustrates Life Cycle of a Bug, in The Bugzilla Guide - 3.6.13 Release distributed under the GNU Free Documentation License.
This said, ITSs provide a rich information about how the project is dealing with some of its most important development processes. For example, they allow for the calculus of time-to-fix for bugs, or time-to-implementation for feature requests. They allow as well for the identification of the persons carrying on most of the maintenance, or the key developers in implementing some kind of new functionality.
In some cases, the ITS carries too processes such as code review or documentation management, which have their own peculiarities.
Code review systems
Code review systems are used, as their name implies, for reviewing source code. Changes to code are organized as patches, which are submited by developers to the system, and then commented and reviewed by reviewers. Depending on the project, maybe only some developers can review, or only some can accept or decline changes.
The information structure of a CRS is quite similar to that of ITS. The role of tickets is taken by proposed patches. Proposed patches go through changes in state as the review cycle progresses. Some reviewers propose to accept the change, some others may ask for a new version, finally the change is accepted or maybe abandoned. All of them (reviewers and change proposers) can write comments as well.
Due to this similarity, some projects use the ITS for code review. This is for example the case of WebKit, which uses Bugzilla. But during the last years, specialized systems for code review have been adopted in most cases. The most prominent cases are Gerrit and GitHub Pull Requests.
Example of code review in Gerrit
Gerrit tracks "changes", usually in combination with git. Each change is a commit, which is reviewed by flagging it with +1 (proposal for accepting the change) or -1 (proposal for asking for a new version of the change). Each version of a change is called "patchset", and the developer is expected to submit one patchset after another until reviewers are happy with the change. In this case, the acceptance of the change is signalled by flaging it with +2. Gerrit can be tuned to the specific policies of a project, so that for example a certain number of +2 is needed to accept (merge) a change, or that only core reviewers can flag a change with +2.
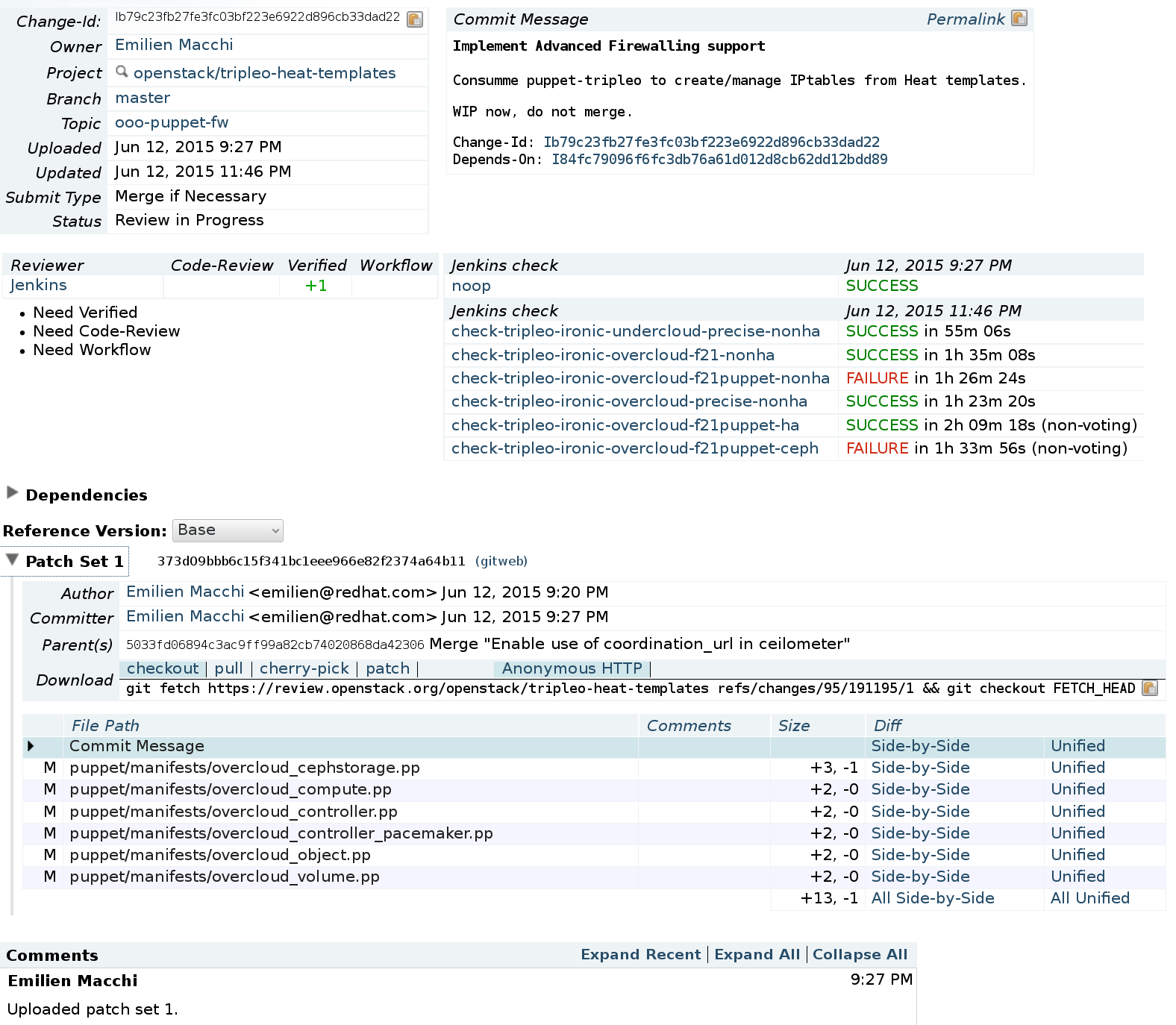 Example of code review: Gerrit code review for OpenStack
Example of code review: Gerrit code review for OpenStack
Gerrit can also be connected with testing and continuous integration systems, so that automated tests are run before and after a change is reviewed. A change submitted to Gerrit finishes its review process, possibly after several patchsets are submitted, when it is accepted (merged), or when the developer decides to withold it (abandon).
Example of code review in GitHub
In GitHub, code review is done via "pull requests", which are a kind of specialized tickets (issues). The process starts when a developer submits a change. To prepare for that, they usually have previously forked the corresponding git repository, and committed the proposed change to it. Then, that commit can be proposed for pull request via the GitHub web interface. Once it is proposed, it appears to GitHub users as a ticket, with the peculiarity that the corresponding change can be explored, commented, and merged.
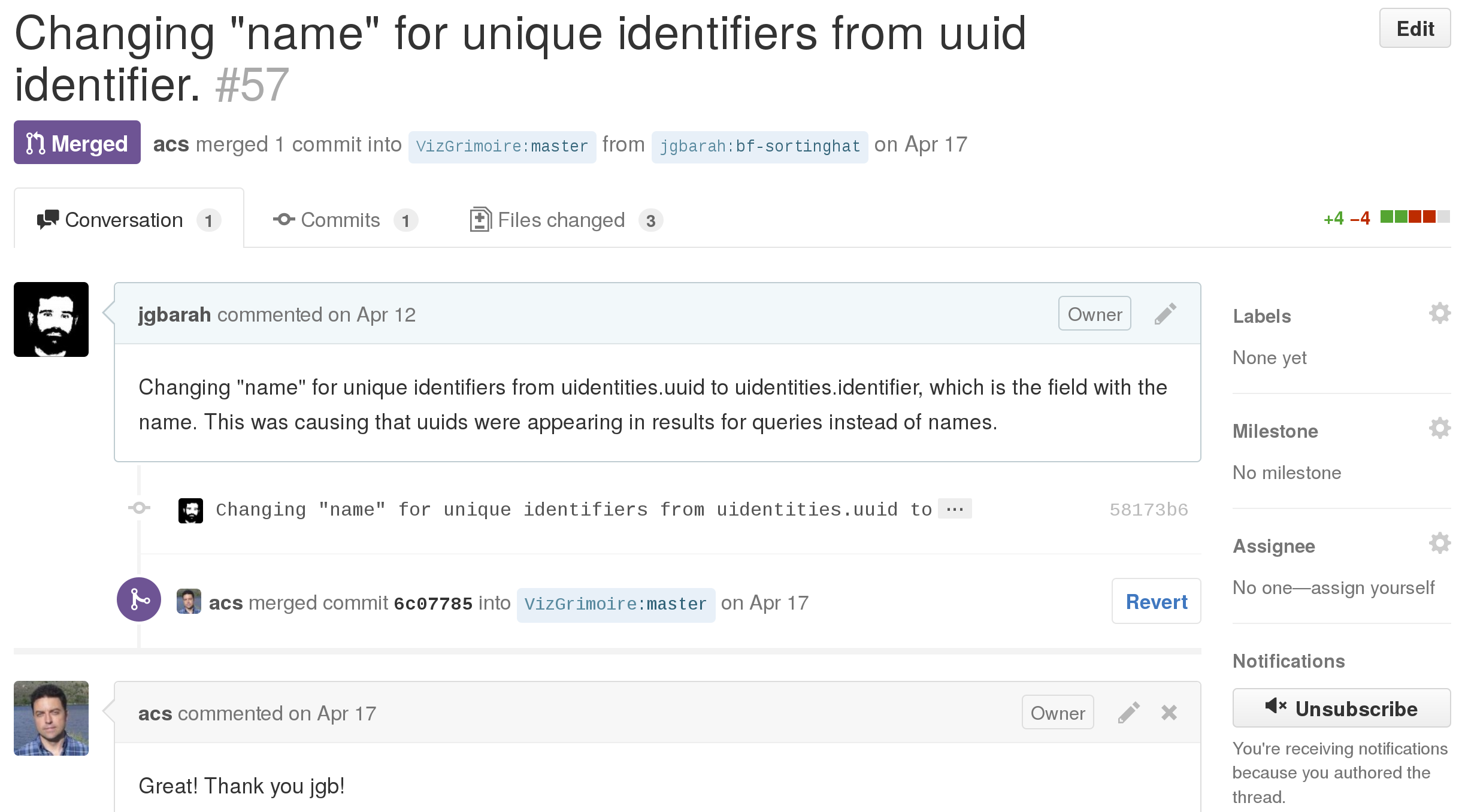 Example of code review: GitHub pull request
Example of code review: GitHub pull request
GitHub does not allow for tracking different versions of the change. In fact, different versions can be submitted, by changing the commit (eg, ammending it). But that information is lost when the corresponding ticket is browsed: only the last version of the change is available.
Since a pull request is really a ticket, it can also be labeled, assigned, closed, etc.
Notes on using information from a CRS
CRS are very important when tracking processes in software development. When a project uses mandatory code review, any new piece of code has to be through the CRS, which tracks times, people involved, etc. Therefore the information mined from it can be used to learn about how long does code review lasts, and who is responsible for delays in code review: developers who fail to submit quiclly new versions of a change, or reviewers who are slow in reviewing it.
People involved in review processes is also a very interesting information. Commit records only keep information about the author and maybe the person merging the commit. Code review provides a much more detailed information: all people commenting, or proposing approval or decline of chaneges are tracked. In addition, CRS usually provide links with testing and continuous integration (CI) systems, which may say a lot about how good proposed changes are.
In many cases, tickets refering bug reports or feture requests corresponding to the change are linked as well. This allows for more complete analysis of all the development process. For example, that allows to track, since the moment a bug is reported to when a fix is proposed, how it evolves to the final merged change, how it finally passes the CI tests, until it is ready for deployment in production environments.
Asynchronous communication systems
In the early ages of FOSS projects, most communication was asynchronous. The most popular tools were email (using mailing lists) and USENET News (in some cases, connected to a mailing list). With time, web forums became important in some communities too, and the relevance of USENET News declined, to the point of fading away. Some special-purpose forums, such as StackOverflow or Reddit, emerged during the last years as important points of communication, even if the projects didn't decide on using them.
Each of of these systems organize information in a different way, although they have some aspects in common. All of them are organized around "messages" (email messages, posts in a forum, questions in StackOverflow, etc.) which have an author, a date, and in most cases a one-line summary. In most cases messages are related in threads, usually as they reply or mention each other. But common aspects stop here. The structure of messages, how threads are organized, and other ancillary information are different from system to sytem.
Example of ACS: email message in Mailman
Mailman is a mailing list manager. You can create mailing lists, and manage them via a website. It has been one of the most usual choices for handling mailing lists during the 2000s. It provides an HTML interface, which gives access to all messages. But it also offers archives in mbox format, which is much easier to mine. The information stored in those archives includes usually most of the headers in the original messages. Below you can find an example of one of those messages, as seen via the HTML interface.
 Example of asynchronous communication: email message in Mailman
Example of asynchronous communication: email message in Mailman
The main fields of information can be seen in this message: the subject (a summary of the message), the sender (including email address, slightly mangled), the date, and the contents. Some other headers may be available.
One important detail is about the date. In most cases, this includes at least the date as stamped by the mail server (usually, Mailman itself). But it can include as well the date of the mailer program user to send the message, usually set to the local time of the sender. This means that both analysis by local time and by universal time are possible.
The contents of the message can be huge, since they may include attachments. Depending on the configuration, attachments may be available or not.
Mailman deals with the list of subscribers to the mailing list, but it doesn't track its history. Therefore, the current list of subscribers can be retrieved, but it is not possible to obtain past lists for a historical analysis.
Privacy sets may interfere with mining, even for public mailing lists. For example, archives can be available only for subscribers, or email addresses may be mangled. Both cases make mining a bit more complicated, or make some analysis impossible.
A final comment: public mailing lists can always be subscribed to. This mean that a miner can subscribe, and produce an archive with all details present in incoming messages. The history before the subscription won't be available, fut from that point on, all details can be easily accessed.
Notes on using information from ACS
It was Apache the first FOSS community to explicitly state that "If it didn't happen on a mailing list, it didn't happen". Since them, but also before them, many others have put in practice this principle, even without stating an specific policy for enforcing it. This means that mailing lists and forums are of great importance to track the coordination activities of projects, and how they discuss and take decisions.
But archives for forums and mailing lists are not always available, or they are available only in part, or they are available in ways that are difficult to mine. For example, some projects don't keep archives of some periods of their history, or rely on systems that even when they perform archiving, are very mining-unfriendly. A notable case is Google Groups, which is used as the ACS by many projects. This system doesn't have an API for mining information, which means that web spidering is the only way to retrieve information. On the contrary, several mailing lists software (such as Mailman) and systems (such as GMane) have very good facilities for automatically retrieving archived information.
Privacy of email addresses is a bit problem for mailing lists archives, but also for mailing list miners. To prevent spam, may archives mangle mailing lists, in a way that it is impossible to know the actual email address of the sender of a message. This means that identification of developers cannot be done based on email addresses, as it can be done for example for git repositories. Therefore, it is not possible to know if a certain poster is the same person that authored a commit. Some types of analysis and evaluation, which rely on this identification, can therefore not be done in those cases. An example is the analysis of how many developers participate in a mailing list.
Forums have also their own problems. First of all, each forum has its own peculiarities. Some of them have APIs which make mining very simple. But some others have APIs not really designed for mining, lacking fundamental capabilities like incremental searching of posts, which makes it complex and resource-demanding to retrieve their information. In some other cases, APIs simply don't exist, and the only way to mine messages is to get database dumps for all the infomation they store, which is obviously difficult.
Synchronous communication systems
The traditional synchronous communication system of choice in FOSS projects has been IRC (Internet Relay Chat). Those are used for casual conversation, support to users, quick discussions between developers, and even for socializing.
Other communication channels used by FOSS projects have been those based on XMPP, such as those provided by Jabber, and more recently, Slack.
The information obtained from all these systems can be organized in a similar way. The unit of communication is the message, which can be related to its author, and to the date it was posted. In most of these systems, communication is organized in channels, and therefore messages can be related to a channel as well.
Example of SCS: IRC log
IRC channels on Freenode are one of the most popular synchronous communication channels used by FOSS projects. People participating in the channels use some software to connect to Freenode. That software lets them see all messages posted to the channel while they are connected, and send messages as well. The software also informs about who is connected to the channel, and produces notifications when new people join or leave it.
To log all these interactions, usually IRC bots are used. Those are programs that connect to the channel, and record all interactions received from it. These bots produce files with those logs that the project uses to make conversations public, and to preserve them for the future.
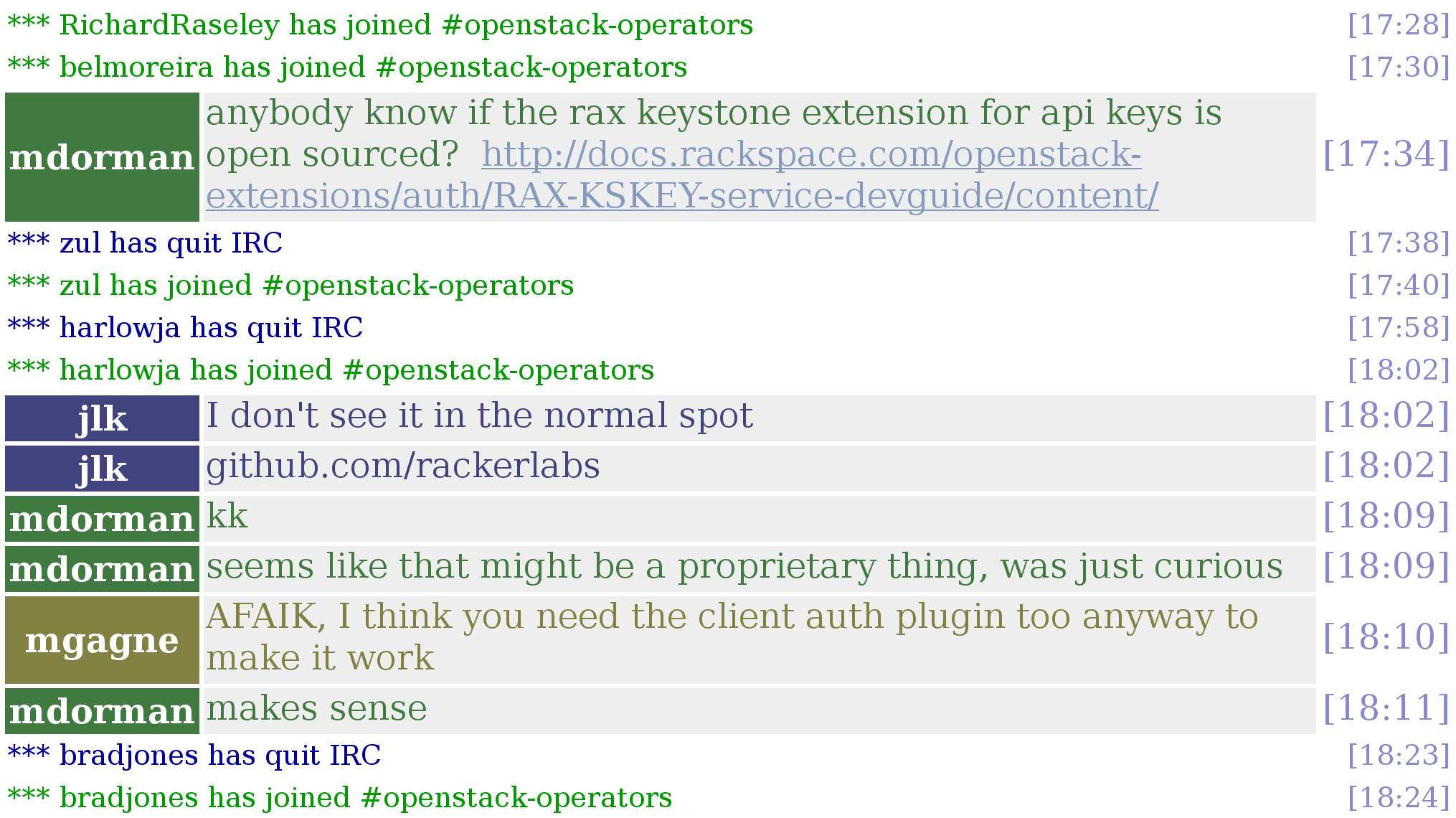 Example of SCS: Log of the #openstack-operators IRC channel of the OpenStack project.
Example of SCS: Log of the #openstack-operators IRC channel of the OpenStack project.
The figure above shows a fraction of the log produced by one of these bots. It can be seen how both messages and join/leave notifications are recorded, and how for each of them the time is available (the date is implicit, since one log file is produced per day). The identifier for the person sending each message or entering or leaving the channel is recorded as well.
In IRC servers, person identifiers can be reserved, so it is usual that frequent participants use always the same name. But this is not always the case: non registered identifiers are available for anyone to use.
Notes on using information from SCS
One of the main trouble with SCS systems is that it is not usually easy to track the identities of people participating in the channels. Nothing like email addresses is available. Although the regulars in the channels are usually identifiable, for most participants this is not the case.
In some cases there are privacy concerns with logging SCS channels. Although they are usually public, to comply with the openness that most project mandate, they are not perceived by some developers as mailing lists are. Due to their immediacy, people may be inclined to forget that what they say is public, and may find themselves saying words that they wouldn't really say in public. When bots are used for recording, some people may be reluctant to participate, for fearing that those cases are recorded and linked with them in public. However, although these concerns exist, public channels are really public, and most projects are dealing with them exactly as they do with public mailing lists: recording, archiving, and making archives public.
SCS recordings are a good data source to check for people with high involvement in the project. Being available for participating in discussions with anyone joining the channel, or answering quick questions, are signals that can be interesting to track.
Testing and continuous integration systems
During the last years more and more projects are including an infrastructure for performing automatic testing. Continuous integration, when used by projects, usually require that those tests are run for each change, so that automatic tools can decide whether it is safe to integrate the change. When the project is using code review, automated testing is usually a part of any review cycle, to spare time to reviewers, who can focus on those changes that passed the testing process.
Some of the most used systems for continuous integration in FOSS projects are Jenkins / Hudson and Travis.
Impact on the infrastructure of the projects
Mining may have a significant impact on the performance of the infrastructure of the project. In fact, some mining activities can be identified by the sysadmins for that infrastructure as a kind of DoS (denial of service) attack. But even when they are not, those activities can cause a log of stress in the project infrastructure. For example, retrieving all information from the ITS, means querying it for all tickets, and the for each ticket obtain all changes and comments. This is not only a significant effort for the ITS, but also an effort for which it was not really designed.
ITS should provide quickly listings of open tickets, or recent tickets assigned to some developers, or the most recent status for a certain ticket. But the actions performed by programs retrieving information for mining are very different from this "usual behavior".
There are some practices that should be followed to ensure that impact on the project infrastructure is minimum:
- Design the retrieving tools as much repository-friendly as possible. For example, use delays between operations, so that the system is not "hijacked" by the program, letting users perform their tasks
- Contact the project for advice in case it is anticipated that the infrastructure is going to be stressed. Project sysdamins can help to design retrieving scenarios that cause as little harm as possible.
- Whenever possible, use archives with previously retrieved information. In this case, the information is retrieved only once, but can be later consumed for many different studies by different parties. If the information is reliable enough, there is no need to stress the infrastructure once and again. In addition, you don't have to retrieve the information yourself, and can concentrate in designing and performing your analysis.